Federated learning: Challenges, methods, and future directions(2020)
Li, Tian, et al. “Federated learning: Challenges, methods, and future directions.” IEEE signal processing magazine 37.3 (2020): 50-60.
- Federated Learning
데이터가 분산된 환경에서 프라이버시를 유지하며 통합 모델을 학습하는 새로운 패러다임
데이터가 중앙 서버로 이동하지 않고, 로컬 기기에서 모델 학습이 이루어짐.
- Problem formulation
Single global statistical model
Objective function: \(\text{min}_wF(w), \text{where } F(w):= \sum^m_{k=1}p_kF_k(w).\)
m은 device 갯수, \(F_k\)는 각 device의 목적함수
가중치 \(p_k\)는 동일하게 1/n 혹은 데이터 갯수대로 (\(n_k/n\))
- Core challenges
1. Expensive communication:
limited resources → communication-efficient methods 필요
접근 가능 방식 2가지:
reducing the total number of communication rounds
reducing the size of the transmitted messages at each round
Local updating
reducing the total number of communication round 방법.
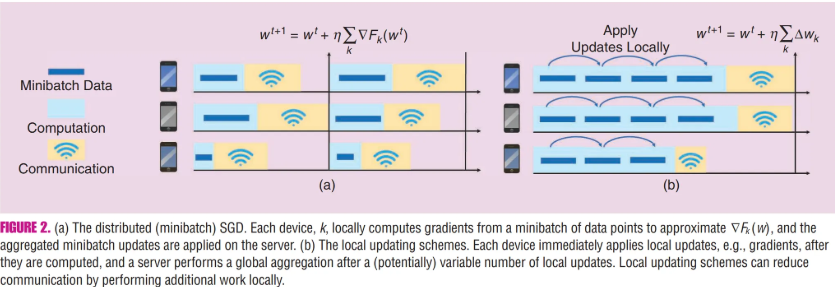
각 기기(device)에서 데이터를 기반으로 여러 단계의 계산(SGD)을 수행한 뒤 중앙 서버와 결과를 공유
- 이는 기기 간 통신을 줄이고 계산과 통신 간의 균형을 맞추는 데 효과적
대표적인 방법이 Federated Averaging(FedAvg), 로컬에서 계산한 SGD 업데이트를 평균 내어 중앙 서버에 전송하는 대표적 방법
- 비볼록(non-convex) 문제에서도 성능이 우수하지만 기기 간 데이터가 Non-IID 인 경우 수렴 보장이 어렵고 성능 저하 발생 가능
Compression schemes
통신 비용을 줄이기 위한 방법. 모델 업데이트를 압축하여 전송 크기를 줄이고 네트워크 자원을 효율적으로 사용하는 것을 목표로 함
- Sparsification (희소화)
- 모델 업데이트의 많은 요소가 중요하지 않음 을 활용하여, 업데이트 중 가장 중요한 일부 값(예: 큰 그래디언트 값)만 전송
- Quantization (양자화)
- 업데이트 값의 정밀도를 줄이는 방법. 예를 들어 32비트 부동소수점 대신 8비트 정수로 값을 포현하여 데이터 크기를 줄임
- Structured Compression
- 모델 파라미터를 특정 구조(예: 저랭크 행렬 형태)로 제한하여 데이터 크기를 줄임
- Randomized Techniques
- 업데이트 값에 무작위 변환을 적용해 압축하고, 복구 가능한 형태로 중앙 서버에 전송
한계점:
데이터의 압축으로 모델의 정확도가 감소할 가능성
통신과 계산 간 트레이드오프: 압축 및 복구 과정에서 추가 계산이 필요할 수 있음
FL에서의 적용
기기-서버 간 통신에서 압축된 그래디언트 전송을 통해 데이터 크기 축소
로컬 데이터의 중요성을 반영하여 유연하게 압축
통신 비용 감소와 모델 성능 유지 간의 균형을 맞추는 것이 연구의 주요 초점
Decentralized training
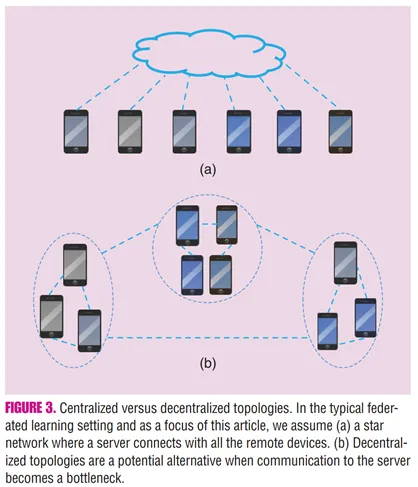
중앙 서버 없이 기기들 간 직접 통신 을 통해 학습을 진행하는 방식
기존의 중앙 집중식 학습 방식(Star Topology)에서 발생하는 통신 병목 현상을 줄이고, 중앙 서버에 대한 의존성을 낮추기 위한 대안으로 제시
각 기기는 로컬 데이터를 기반으로 모델 업데이트를 계산한 뒤, 이웃 기기와 업데이트를 교환. 네트워크는 그래프 형태로 구성, 각 기기는 자신의 이웃들과 주기적으로 정보를 교환하여 전역 모델에 수렴
동기식, 비동기식으로 학습 가능
연구 방향
- 이웃 선택 전략, 그래프 기반 최적화, 비동기 통신 개선 …
2. System heterogeneity
- Variability in hardware (CPU, memory), network connectivity, power, network size … 등 의 차이 때문에 발생
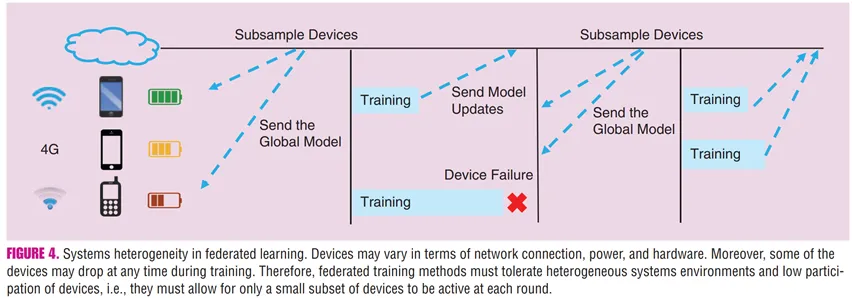
Asynchronous Communication
FL은 네트워크 연결 상태, 하드웨어 성능, 배터리 상태 등 기기 간 시스템 이질성이 매우 크기 때문에 동기화가 어려운 환경이 많음. 이를 해결하기 위해 비동기 통신 방식을 활용, 느린 기기(stragglers)가 전체 학습 과정의 병목이 되는 것을 방지
비동기 통신은 지연 문제를 줄이는 데 효과적이지만, 무제한 지연(unbounded delay)가 FL에서 현실적으로 발생할 수 있어 관리가 필요
- 한계:
모델 업데이트 지연 (staleness):
- 오래된 업데이트가 글로벌 모델에 반영될 수 있으며, 이는 학습 수렴 속도를 저하시키거나 모델 품질을 저하시킬 위험
설계 복잡성 증가:
지연된 업데이트의 영향을 최소화하기 위한 추가적 알고리즘 필요
업데이트의 중요도를 시간에 따라 가중치로 조정하거나 지연된 업데이트를 무시하는 전략이 요구
Active Sampling
FL에서 중앙 서버가 특정 기기를 선택적으로 학습에 참여시키는 방식을 의미
대부분 FL 메서드는 수동적 참여(passive participation) 방식으로, 임의의 기기들이 학습에 참여
이 방식은 기기들의 시스템 자원 상태(네트워크, 계산능력, 배터리)나 통계적 대표성을 기반으로 효율적이고 대표성 있는 기기를 선택하여 학습 성능을 향상시키려는 방법
- 필요성
대부분 FL 환경에서는 동시에 활동 가능한 기기 수가 제한적. 네트워크 기기들이 충분히 참여하지 않으면 글로벌 모델의 품질이 떨어질 수 있다.
일부 기기는 네트워크, 배터리 상태, 처리 능력이 제한되어 있으며 데이터가 Non-IID 분포일 가능성이 크다.
- 한계점
기기 간 데이터 편향: 특정 기기들만 지속적으로 선택될 경우, 글로벌 모델이 편향 될 위험
복잡한 설계 요구: 기기 상태와 통계적 특성을 실시간으로 분석하고 최적의 샘플링을 수행하기 위한 추가 설계가 필요
Fault Tolerance
학습 중 일부 기기(device)가 작업을 중단하거나 네트워크에서 이탈해도 전체 학습 과정이 중단되지 않고 안정적으로 진행되도록 설계하는 기술
FL 에서는 네트워크 연결이 불안정하거나 배터리가 부족한 기기가 자주 발생, 이런 기기의 중단은 학습 모델에 편향(bias)를 초래할 가능성
중단된 기기가 포함했던 데이터가 특정 분포를 가지는 경우, 글로벌 모델이 특정 데이터를 학습하지 못해 편향된 모델이 생성될 수 있음
- 전략
- 중단 기기의 무시 / 부분 업데이트 수용 / 코딩(computation coding) 활용
3. Statistical heterogeneity
FL 환경에서 각 기기의 데이터는 Non-IID 데이터일 가능성이 높다. (사용자별 언어 사용 패턴이 다른 모바일 기기, 지역별로 특성이 다른 의료 데이터)
이러한 통계적 이질성은 글로벌 모델 학습 과정에서 문제를 야기, 특히 일반화 성능과 학습 수렴 속도에 부정적인 영향
또한 iid 가정을 위반.
“multitask”, “metalearning” 관점에서 personalized 또는 device specific modeling이 가능. 이는 더 나은 personalization을 위한 데이터의 statistical heterogeneity를 다루는 자연스런 방법
Modeling heterogeneous data
- 주요 과제
Non-IID 데이터 처리
모델 수렴 보장 어려움
- FedAvg 등은 Non-IID 데이터를 처리할 때 수렴이 불안정하거나 학습 속도가 저하되는 문제 발생
개인화(personalization)의 필요성
- 단일 글로벌 모델로 모든 기기의 데이터를 일반화하는 대신, 기기별 또는 그룹별로 맞춤형 모델을 학습할 필요가 있음
- 접근 방법
Multi-task learning
- Multi-Objective Optimization for Communication-efficient Heterogeneous Agents(MOCHA)는 각 기기에 대해 서로 다른 로컬 모델을 학습하면서, 기기 간의 관계를 활용하여 공유표현(shared representation)을 학습.
Bayesian Methods
- FL을 베이지안 네트워크로 모델링하여, 기기별 데이터를 분포적으로 표현하고 변분 추론(variational inference)을 통해 모델 학습
Meta-Learning
- 각 기기를 독립적인 학습 문제로 간주하고, 글로벌 모델이 이러한 문제들에서 빠르게 적응할 수 있도록 학습
Pluralistic Modeling
- 글로벌 모델과 기기별 모델 간 적응적 선택을 통해 상황에 따라 글로벌 모델 또는 로컬 모델을 활용
Convergence guarantees for non-i.i.d. data
FedAvg의 Non-IID 문제
기존의 병렬 SGD와 관련된 분석은 데이터가 i.i.d. 조건을 충족한다고 가정하여, 각 로컬 업데이트가 동일한 확률 분포를 따르는 것으로 간주.
하지만 FL에서는 기기간 데이터 분포가 다르기에 FedAvg와 같은 알고리즘은 업데이트가 동일한 확률 과정(stochastic process)이 아니게 되어 수렴 보장이 어렵다.
- 접근 방법
Heuristic Approaches: 서버 측에서 공통 데이터를 생성하거나 공유 데이터(proxy data) 를 활용해 기기 간 분포 차이를 줄이는 방법
But, 네트워크 대역폭 부담 증가, 데이터 프라이버시 정책 위반 가능
4. Privacy concerns
FL는 raw data 대신 gradient information 등을 공유.
privacy를 지키려다가 모델 퍼포먼스가 줄거나 시스템 효율성이 나빠지곤 함
Privacy in machine learning
FL 과 같은 분산 학습 환경에서는 원시 데이터를 서버로 전송하지 않지만, 모델 업데이트 자체도 민감한 정보를 포함할 수 있어 추가적인 프라이버시 보호가 필요
Differential privacy
모델 학습과정에서 발생하는 데이터 노출을 방지하기 위해 노이즈를 추가하여 민감한 정보를 보호하는 방법
→ 노이즈 추가로 인해 모델 성능 저하가 발생할 수 있음
Homomorphic Encryption
암호화된 상태에서 연산할 수 있도록 허용하는 기법. 계산비용이 매우 높아 대규모 모델 학습에는 제한적
Secure Function Evaluation(SFE), Secure Multiparty Computation(SMC)
여러 당사자가 데이터의 실제 내용을 공유하지 않고 공동 연산을 수행하는 기법.
Privacy in federated learning
- FL은 원시 데이터를 로컬 기기에서 유지하면서 모델을 학습하기 때문에 기본적으로 프라이버시 보호를 염두에 둔 학습 방식. 그러나 모델 업데이트(예: 그래디언트 정보)를 공유하는 과정에서 민감한 정보가 유출될 가능성이 존재.
- 프라이버시 정의
Global Privacy: 모델 업데이트는 중앙 서버에만 공개되고, 서버 외의 제 3자에게는 비공개. 중앙 서버는 신뢰할 수 있다고 가정.
Local Privacy: 모델 업데이트가 중앙 서버에도 비공개로 처리됨. 서버가 신뢰할 수 없거나 악의적일 가능성을 고려한 방식.
- Future Direction
1. Extreme Communication Efficiency
모델 학습 중 통신의 빈도나 크기를 최소화 하는 방법 연구 One-shot learning이나 Divide-and-conquer 방식의 FL 도입
통신 비용과 모델 성능간의 Pareto Frontier 분석, 다양한 통신-정확도 트레이드 오프 시나리오에서 가장 효과적인 접근법 탐색
2. Heterogeneity Diagnositcs
기기 간 데이터 및 시스템 이질성을 빠르고 정확하게 진단
- 진단 메트릭 개발 및 진단 결과를 기반으로 최적의 학습 알고리즘 설계
3. Asynchronous Communication
비동기 방식으로 기기의 비정상적인 작동을 수용하면서 학습 안정성 보장
- 모델 업데이트 지연(staleness) 제어: 오래된 업데이트의 영향을 최소화하는 전략 연구