4. 코딩 테스트 필수 문법
코딩 테스트 합격자 되기 - 파이썬 편 책 정리 내용입니다.
04-1 빌트인 데이터 타입
빌트인 데이터 타입(built-in data type)
기본 데이터 타입: 정수형(int), 부동소수형(float), 문자열
컬렉션 데이터 타입: 리스트, 튜플, 셋, 딕셔너리
정수형
- 양의 정수, 음의 정수, 0
부동소수형
소수를 저장할 때 사용
※파이썬은 부동소수형 데이터를 이진법으로 표현하기에 오차(엡실론, epsilon)가 발생한다. 항상 주의
04-2 컬렉션 데이터 타입
컬렉션: 여러 값을 담는 데이터 타입
- 리스트(list), 튜플(tuple), 딕셔너리(dictionary), 셋(set), 문자열(string) 등이 있다.
데이터의 수정 가능 여부에 따라
변경할 수 있는 객체(mutable object)
변경할 수 없는 객체(immutable object)
이렇게 2가지로 구분된다.
뮤터블 객체 : 리스트, 딕셔너리,
이뮤터블 객체: 정수, 부동 소수점, 튜플
리스트
뮤터블 객체
[ ]로 원소를 감싸는 형태로 사용
시퀀스(순서)가 있는 자료형
여러 개의 데이터를 순차적으로 저장할 수 있는 가변 길이 배열
- 리스트 인덱싱: 인덱스를 활용해서 특정 위치의 원소에 접근하는 것
- 리스트 슬라이싱: 시퀀스 자료형의 범위를 지정해서 값들을 복사하여 가져오는 방식. 파이썬 코드로 아래와 같이 사용
- 음수 인덱스?
my_list의 원소가 [1, 2, 3, 4, 5] 라고 하면,
0 1 2 3 4
[1, 2, 3, 4, 5]
-5 -4 -3 -2 -1
가운데 행인 리스트를 기준으로 위가 양수 인덱스, 아래가 음수 인덱스이다.
위의 [-4:-2] 의 경우엔, -4 인덱스부터 -2 인덱스 앞 까지 출력이므로 [2, 3] 가 출력된다.
리스트 컴프리 헨션 (List Comprehension)
기본 구조는 아래와 같다.
표현식: 리스트의 각 요소에 적용할 표현식
항목: 반복 가능한 객체(예: 리스트, 문자열, 범위 등)에서 가져온 요소
반복 가능한 객체: 리스트를 생성할 때 반복할 객체
if 조건 (option): 조건이 참일 경우에만 요소를 리스트에 추가한다.
장점:
간결함: 코드가 짧고 명확해진다.
성능: 일반적인 for 루프보다 더 빠르게 동작할 수 있다.
가독성: 조건부 논리와 반복문을 한 줄에 표현할 수 있어 코드의 가독성이 높아진다.
예제
- 예제 1. 0부터 4까지의 제곱수를 가진 리스트 생성
# 0부터 4까지의 숫자를 생성하여 각 숫자의 제곱을 계산한 리스트를 생성
squares = [x ** 2 for x in range(5)]
# range(5)는 0, 1, 2, 3, 4를 생성
# x**2는 각 x의 제곱을 계산
print(squares) # [0, 1, 4, 9, 16][0, 1, 4, 9, 16]- 예제 2. 짝수만 필터링한 리스트 생성
# 0부터 9까지의 숫자 중에서 짝수만 선택하여 리스트를 생성
evens = [x for x in range(10) if x%2 == 0]
# range(10)은 0부터 9까지의 숫자를 생성
# if x % 2 == 0 조건은 짝수인 경우에만 리스트에 추가
print(evens) # [0, 2, 4, 6, 8][0, 2, 4, 6, 8]- 예제 3. 문자열 리스트에서 특정 조건을 만족하는 요소 선택
# 'a' 문자가 포함된 과일 이름들만 선택하여 리스트를 생성
fruits = ['apple', 'banana', 'cherry', 'date']
selected_fruits = [fruit for fruit in fruits if 'a' in fruit]
# fruits 리스트를 순회하면서 'a'가 포함된 fruit만 리스트에 추가
print(selected_fruits)['apple', 'banana', 'date']- 예제 4. 중첩 반복문을 이용한 리스트 컴프리헨션
# 3x3 행렬의 모든 좌표 쌍을 생성
pairs = [(x, y) for x in range(3) for y in range(3)]
# 첫 번째 for문은 x에 대해 0, 1, 2를 순회
# 두 번째 for문은 y에 대해 0, 1, 2를 순회
# 각 (x, y) 쌍이 리스트에 추가
print(pairs)[(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]예제 5. 중첩된 리스트 컴프리헨션
# 중첩 리스트를 평탄화하여 하나의 리스트를 만든다.
matrix = [[1,2,3], [4,5,6], [7,8,9]]
flat_list = [num for row in matrix for num in row]
# 첫 번째 for문은 각 행(row)에 대해 순회
# 두 번째 for문은 각 행의 요소(num)에 대해 순회하여 num을 리스트에 추가
print(flat_list)[1, 2, 3, 4, 5, 6, 7, 8, 9]예제 6. 람다 함수와 함께 사용하는 리스트 컴프리헨션
# 리스트의 각 요소에 람다 함수를 적용하여 새로운 리스트를 생성
numbers = [1, 2, 3, 4, 5]
squared_numbers = [(lambda x: x**2)(x) for x in numbers]
# numbers 리스트의 각 요소 x에 대해 람다 함수 (lambda x: x**2)를 적용하여 제곱값을 계산
print(squared_numbers)[1, 4, 9, 16, 25]리스트의 시간복잡도
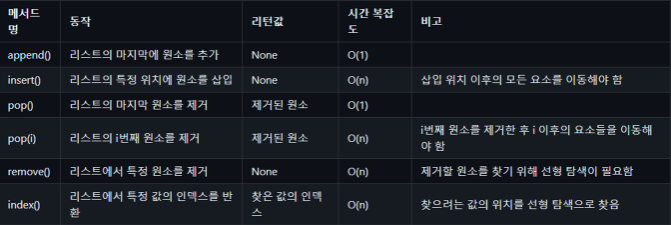
리스트의 임의 접근 시간복잡도는 O(n)이고,
데이터를 삽입할 때의 시간복잡도는 맨 앞은 O(1), 중간이나 맨 뒤는 O(n)이다.
딕셔너리
뮤터블 객체
키(key)와 값(value) 쌍을 저장하는 해시 테이블로 구현
키를 사용하여 값을 검색하는 자료형. 이 때 키는 이뮤터블 객체여야 한다. (변경되면 안되기 때문)
각 키는 고유하며, 이를 통해 값을 빠르게 검색할 수 있다.
딕셔너리 초기화
- 딕셔너리 삽입과 출력
# 딕셔너리 값 삽입
my_dict["apple"] = 1
my_dict["banana"] = 2
my_dict["orange"] = 3
# 딕셔너리 값 출력
print(my_dict){'apple': 1, 'banana': 2, 'orange': 3}- 딕셔너리 검색
- 딕셔너리 수정
- 딕셔너리 삭제
※ 딕셔너리에 키가 없는 경우 예외가 발생하므로 예외 처리를 해주어야 한다.
# 딕셔너리 생성
my_dict = {"apple": 1, "banana": 2, "cherry": 3}
# my_dict에 없는 key로 설정
key = "kiwi"
# 키가 딕셔너리에 있는지 확인
if key in my_dict:
# 키가 딕셔너리에 있으면 해당 값 출력
print(f"값: {my_dict[key]}")
else:
# 키가 딕셔너리에 없으면 에러 메시지 출력
print(f"'{key}'키가 딕셔너리에 없습니다.")'kiwi'키가 딕셔너리에 없습니다.딕셔너리의 시간 복잡도
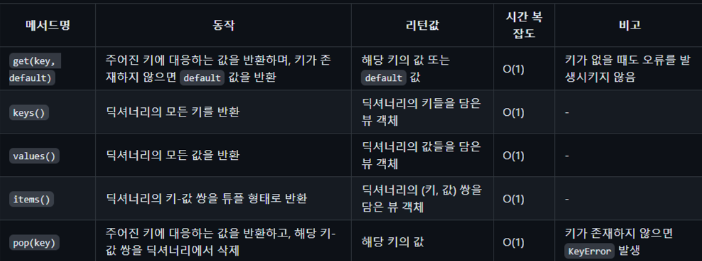
셋
해시 테이블로 구현되어 있어 대부분의 작업이 매우 빠르게 수행된다.
중복된 데이터를 허용하지 않는 데이터 구조이다. 데이터의 순서가 중요하지 않은 경우 사용된다.
중괄호 {}를 사용해 정의한다. 각 요소는 고유해야한다.
? 리스트와의 차이점?
셋은 중복된 값을 허용하지 않으며 순서가 중요하지 않다.
셋의 시간 복잡도
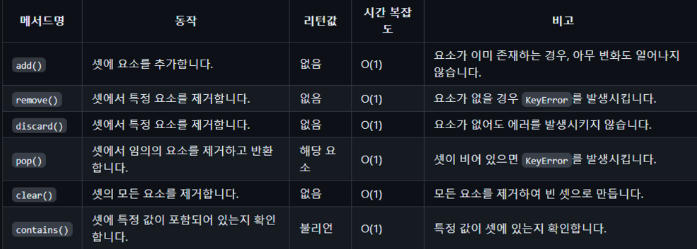
튜플
이뮤터블 객체이다. 리스트, 딕셔너리와 달리 한 번 생성하면 삽입하거나 삭제할 수 없다.
튜플 초기화
- 튜플 인덱싱, 슬라이싱
? 리스트가 있는데 튜플을 사용하는 이유?
튜플은 ‘값을 바꿀 수 없는’ 이뮤터블 데이터 타입이므로 코딩 테스트에서 값이 변경되지 않아야 하는 데이터에 사용하여 실수를 방지할 수 있다.
튜플의 시간복잡도
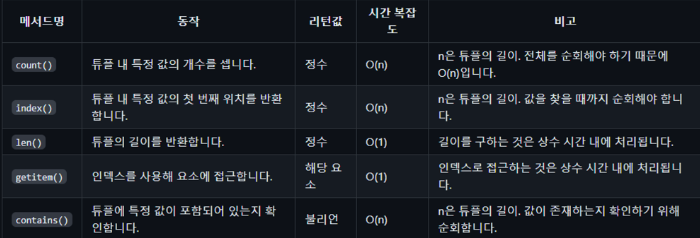
문자열
- 큰 따옴표나 작은 따옴표로 감싸 사용한다.
- 문자열 추가, 삭제: 문자열은 이뮤터블 객체이므로 기존 객체를 수정하는 것이 아니라 새로운 객체를 반환.
문자열 수정: replace() 메서드를 사용하여 가능! 첫 번째 인수에 찾을 문자열을, 두 번째 인수에 변경할 문자열을 넣어 사용
예를 들어 replace(A, B)는 A를 모두 찾아 B로 변경
04-3 함수
함수 정의
함수 호출
람다식
람다식(lambda expression)은 함수를 간단하게 표현하는 방법. 또한 익명 함수(anonymous function)을 만드는 데 사용
- 익명 함수: 이름이 없는 함수, 코드에서 딱 한 번 실행할 목적으로 사용하거나, 다른 함수의 인수로 사용하는데 쓰임
람다 함수의 기본 구조
람다 함수는 lambda 키워드를 사용하여 정의되며, 다음과 같은 구조를 가진다.
lambda키워드는 람다 함수를 정의인수: 람다 함수에 전달되는 입력값표현식: 인수를 사용하여 계산될 단일 표현식. 이 표현식의 결과가 함수의 반환값이 된다.
람다식 정의
람다식 사용
- 람다식은 변수로 참조할 수 있다.
- 인수로 람다식을 넘기는 방법
예제
- 예제 1. 간단한 덧셈 람다 함수
- 예제 2. 리스트 정렬에서의 람다 함수 사용
함수형 프로그래밍과 람다 함수
함수형 프로그래밍은 프로그래밍 패러다임 중 하나로, 순수 함수와 상태가 없는 데이터 처리를 강조한다. 이는 같은 입력이 주어지면 항상 같은 출력을 내는 함수로 프로그램을 구성하는 방식을 의미한다. 함수형 프로그래밍은 다음과 같은 주요 특징을 가진다.
순수 함수: 외부 상태를 변경하지 않고, 같은 입력값에 대해 항상 같은 출력을 반환하는 함수
불변성: 데이터는 한 번 생성되면 변경되지 않는다. 데이터의 변경이 필요한 경우, 새로운 데이터를 생성하여 사용한다.
고차 함수(Higher-order Functions): 다른 함수를 인수로 받거나, 함수를 반환하는 함수. 고차 함수는 함수형 프로그래밍의 중요한 개념
람다 함수는 이러한 함수형 프로그래밍의 개념을 실현하는 도구로써, 파이썬에서 간결하고 명확한 코드를 작성하는 데 매우 유용
- 예제 3. map() 함수와 람다 함수
# 리스트의 각 요소를 제곱하는 예제
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
# map 함수는 리스트의 각 요소에 대해 람다 함수를 적용하여 제곱값을 계산
print(squared_numbers)[1, 4, 9, 16, 25]- 예제 4. filter() 함수와 람다 함수
일급 객체 (First-Class Object)와 람다 함수
파이썬에서 함수는 일급 객체로 취급된다. 일급 객체란, 프로그래밍 언어에서 다음과 같은 특성을 가지는 객체를 의미한다.
변수나 데이터 구조에 할당할 수 있다.
다른 함수의 인수로 전달할 수 있다.
다른 함수의 반환값으로 사용할 수 있다.
이러한 특성 덕분에, 파이썬의 함수는 매우 유연하게 사용될 수 있다. 아래는 이러한 특성을 설명하는 예제들이다.
- 예제 5. 함수의 변수 할당
# 함수 정의
def greet(name):
return f"Hello, {name}!"
# 함수를 변수에 할당
greeting = greet
# 변수를 통해 함수 호출
print(greeting("Alice"))Hello, Alice!- 예제 6. 함수의 인수로 함수 전달
# 함수 정의
def call_function(func, value):
return func(value)
# 람다 함수를 인수로 전달
result = call_function(lambda x: x**2, 5)
print(result)25- 예제 7. 함수의 반환값으로 함수 사용
# 함수 정의
def make_multiplier(factor):
return lambda x: x * factor
# 함수 반환값으로 람다 함수 사용
double = make_multiplier(2)
print(double(10))20람다 함수는 이러한 일급 객체의 특성을 최대한 활용하여 간단하게 익명 함수를 정의할 수 있는 수단을 제공한다. 특히, 일시적인 연산을 위해 짧고 단순한 함수를 정의할 때 매우 유용하다. 람다 함수는 코드의 간결함과 명확성을 제공하며, 함수형 프로그래밍에서 중요한 역할을 한다.
04-4 코딩 테스트 코드 구현 노하우
조기 반환
조기 반환(early return)은 코드 실행 과정이 함수 끝까지 도달하기 전에 반환하는 기법
코드의 가독성을 높여줌
예외를 조금 더 깔끔하고 빠르게 처리 가능
보호 구문
보호 구문(guard clauses)은 본격적인 로직을 진행하기 전 예외 처리 코드를 추가하는 기법.
예를 들어 조건문을 이용하여 초기에 입력값이 유효한지 검사하고 그렇지 않으면 바로 함수를 종료
def calculate_average(numbers):
if numbers is None: # 값이 없으면 종료(예외)
return None
if not isinstance(numbers, list): # numbers가 리스트가 아니면 종료(예외)
return None
if len(numbers) == 0: # numbers의 길이가 0이면 종료(예외)
return None
total = sum(numbers)
average = total / len(numbers)
return average
numbers = []
print(calculate_average(numbers))None- 이렇게 구현한 코드는 보호 구문 이후 구현부에서 입력값에 대한 예외를 고려하지 않아도 되므로 보기 좋다.
합성 함수
- 합성 함수(composite method)는 2개 이상의 함수를 활용하여 함수를 추가로 만드는 기법. 보통 합성 함수는 람다식을 활용
Summary
파이썬의 빌트인 데이터 타입은 기본 타입(정수형, 부동소수형, 문자열)과 컬렉션 타입(리스트, 딕셔너리, 튜플, 셋)이 있다.
파이썬의 데이터 타입은 이뮤터블(값을 변경할 수 없음) 타입과 뮤터블(값을 변경할 수 있음) 타입으로 나눌 수 있다. 이뮤터블 타입은 기본 타입, 문자열, 튜플이 있고 뮤터블 타입은 리스트, 딕셔너리, 셋이 있다.
함수는 프로그램의 기본 구성 요소로 파이썬에서는 예약어로 def로 정의할 수 있다.
람다식은 간결한 함수 표현 방법이다. 한번만 사용하거나 인자로 함수를 넘겨야 할 경우 유용하다.
조기 반환, 보호 구문, 합성 함수 등의 기법을 활용하면 코드의 가독성과 효율성을 높일 수 있다.
추가 질문
성능 비교 문제
? 리스트에서 pop(0)과 collections.deque.popleft()의 동작 방식이 어떻게 다르며, 성능 차이가 나는 이유를 설명해주세요.
리스트의
pop(0):리스트는 동적 배열로
pop(0)은 리스트의 첫 번째 요소를 제거하고 반환한다. 이 후 모든 요소들을 앞으로 옮기는 작업이 필요하기에 시간 복잡도는 O(n)이다.collections.deque.popleft():deque의
popleft()는 첫 번째 요소를 제거하고 반환한다. 앞으로 옮기는 작업이 필요 없기에 시간 복잡도는 O(1)이다.리스트는 모든 요소들을 앞으로 옮기는 작업이 필요하기에 시간이 많이 소요된다.
큰 데이터셋에서 첫 번째 요소를 자주 제거하는 작업이 필요하면 deque을 사용하는 것이 좋다.
? 리스트와 셋(set)에서의 데이터 추가 및 삭제의 시간 복잡도를 비교해주세요.
리스트의 경우 끝에 요소를 추가하는 경우 O(1)이다. 하지만 위치 조정까지 한다면 O(n)까지 늘어날 수 있다. 삭제는 최악의 경우 O(n)이다.
셋은 해시 테이블로 구현되어있어 추가와 삭제가 모두 평균적으로 O(1)이다.
? 주어진 데이터에서 고유한 값을 찾아야 할 때, 리스트와 셋(Set) 중 어떤 컬렉션을 사용하는 것이 더 효율적인지 설명하고 이유를 서술해주세요.
- 셋이 더 효율적이다. 셋은 1개의 원소만을 담기 때문에 고유한 값을 찾기에 좋다. 또한 리스트는 모두 탐색하는데 O(n)이 걸리지만, 셋은 O(1)이 걸리므로 셋이 더 유리하다.
코딩 문제
- 리스트의 중복 제거 및 정렬
리스트 lst가 주어졌을 때, 리스트 내 중복된 요소를 제거하고 남은 요소들을 오름차순으로 정렬한 새로운 리스트를 반환하는 함수 작성
def remove_duplicates_and_sort(lst):
# 구현하세요
lst = set(lst)
lst = sorted(list(lst))
return lst
# 예시
print(remove_duplicates_and_sort([4, 2, 2, 1, 3, 4])) # 출력: [1, 2, 3, 4]
print(remove_duplicates_and_sort([5, 5, 5, 5])) # 출력: [5]
print(remove_duplicates_and_sort([1, 2, 3, 4, 5])) # 출력: [1, 2, 3, 4, 5][1, 2, 3, 4]
[5]
[1, 2, 3, 4, 5]- 딕셔너리 키의 빈도수 계산
문자열 리스트 words가 주어졌을 때, 각 단어가 리스트에 등장하는 빈도수를 딕셔너리로 반환하는 함수를 작성하세요.
def count_word_frequencies(words):
# 구현하세요
freq_dict = dict()
for word in words:
if word in freq_dict:
freq_dict[word] += 1
else:
freq_dict[word] = 1
return freq_dict
# 예시
print(count_word_frequencies(["apple", "banana", "apple", "orange", "banana", "apple"]))
# 출력: {'apple': 3, 'banana': 2, 'orange': 1}
print(count_word_frequencies(["dog", "cat", "dog", "dog", "fish"]))
# 출력: {'dog': 3, 'cat': 1, 'fish': 1}{'apple': 3, 'banana': 2, 'orange': 1}
{'dog': 3, 'cat': 1, 'fish': 1}- 딕셔너리 키 존재 여부 확인
딕셔너리 d와 키 key가 주어졌을 때, 해당 키가 딕셔너리에 존재하는지 여부를 반환하는 함수를 작성하세요.