Deep Learning
「딥러닝 제대로 시작하기」책내용 요약 및 정리



- 역전파법에 의한 신경망 학습이 2층정도의 신경망에선 잘 이뤄졌지만 그보다 많은 층수에선 기대했던 결과를 얻지 못함. 과적합이 나타남. (예외 : CNN)
- 신경망은 학습을 위한 여러 파라미터로 층수나 유닛의 수를 갖는데 이 파라미터가 최종적으로 어떻게 성능으로 이어지는지 알 수 없었음. 파라미터 결정에 노하우는 있지만 이론이 없었음.
이런 이유로 머신러닝보다 뒤떨어진다는 평가를 받음.
역전파법
- 샘플에 대한 신경망의 오차(목표 출력과 실제 출력의 차이)를 다시 출력층에서부터 입력층으로 거꾸로 전파시켜 각 층의 가중치의 기울기를 계산하는 방법
사전훈련
- 사용하려는 신경망을 학습기키기 전 층단위의 학습을 거치는 것으로 더 나은 초기값을 얻는 방법. 딥 러닝 붐의 계기가 되었지만, 필수적인 것만은 아님. CNN같은 경우는 처음부터 사전훈련을 필요로 하지 않는다.
자기부호화기
- 입력으로부터 계산되는 출력이 입력 자체와 비슷해지도록 훈련되는 신경망. 다시말해 자기부호화기의 목표 출력은 입력 그 자체이며, 비지도 학습으로 학습이 이루어진다.
다층 신경망은 파라미터를 랜덤하게 초기화하면 학습이 잘 되지 않지만, 층마다 비지도 학습 형태의 사전훈련을 거친 뒤 얻은 파라미터를 초깃값으로 사용하면 학습이 잘된다고 한다.
-
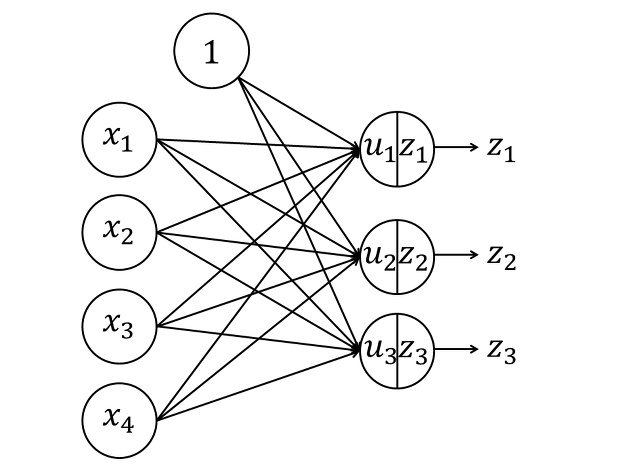
층 모양으로 늘어선 유닛이 인접한 층(layer)들과만 결합하는 구조를 가지며 정보가 입력 측으로부터 출력 측으로 한 방향으로만 흐르는 신경망.
다층 퍼셉트론(multi-layer perceptron)이라 부르기도 한다.신경망을 구성하는 각 유닛은 복수의 입력을 받아 하나의 출력을 계산한다. 입력은 가중치 4개를 받지만, 이 유닛이 받는 총 입력은 다음과 같이 바이어스를 추가하여 5개이다.
$$ u = w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + b $$
- 각 입력마다 다른
가중치(weight)w1, w2, w3, w4를 곱한 값을 모두 합하고, 이에바이어스(bias)라 불리는 값을 더한 값이 된다.
- 이 유닛의 출력 z 는 총 입력 u에 대한
활성화 함수(activation function)라 불리는 함수 f의 함숫값이다.
-
유닛마다 각각 다른 가중치 w가 주어진다
세 개의 유닛이 받는 입력은 각각 다음과 같이 계산된다.
$$ u_1 = w_{11}x_1 + w_{12}x_2 + w_{13}x_3 + w_{14}x_4 + b_1 $$
$$ u_1 = w_{21}x_1 + w_{22}x_2 + w_{23}x_3 + w_{24}x_4 + b_2 $$
$$ u_1 = w_{31}x_1 + w_{32}x_2 + w_{33}x_3 + w_{34}x_4 + b_3 $$
여기에 다시 활성화 함수를 적용하여 아래 식과 같은 출력이 된다.
$$ z_{j} = f(u_{j}) \,\,\,\,\,\,(j = 1, 2, 3) $$
- 유닛의 활성화 함수로는 통상적으로 단조증가하는 비선형함수가 사용된다.
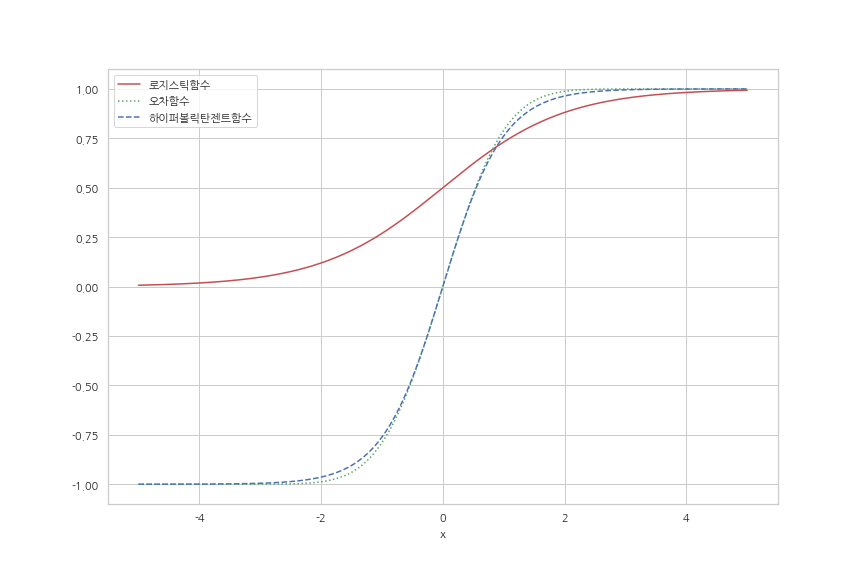
-
로지스틱 함수는 (0, 1)을 치역으로,쌍곡선 정접함수는 (-1, 1)을 치역으로 갖는다. - 로지스틱함수와 쌍곡선 정접함수는 모두 시그모이드 함수이다. 출력이 서서히 그리고 매끄럽게 변화하는 특징을 갖는다. 이러한 특징은 생물의 신경세포가 갖는 성질을 모델링한 것이다.

-
최근에 시그모이드 대신
램프 함수가 자주 사용된다. 간단하게 줄여 rectifier라고도 부른다.램프 함수는 z = u 인 선형 함수 중 u < 0 인 부분을 f(u) = 0으로 바꾼 단순한 함수이다.
위의 두 함수보다 학습이 빠르고 최종 결과가 더 좋은 경우가 많아 현재 가장 많이 사용된다.
이 함수를 갖는 유닛을 ReLU (Rectified Linear Unit)라고 표기하기도 한다.
-
램프 함수와 관계 깊은
맥스아웃은 K개의 유닛을 하나로 합친 것과 같은 구조를 갖는다.각각의 총 입력을 uj1, uj2 ... ujk 별로 따로 계산한 후, 그중 최댓값을 이 유닛의 출력으로 한다.
-
신경망에서는 각 유닛의 활성화 함수가 비선형성을 갖는 것이 본질적으로 중요하지만, 부분적으로 선형사상을 사용하는 경우가 있다.
회귀 문제에선 출력층에서
항등사상을, 클래스 분류에서는소프트맥스 함수를 사용한다.
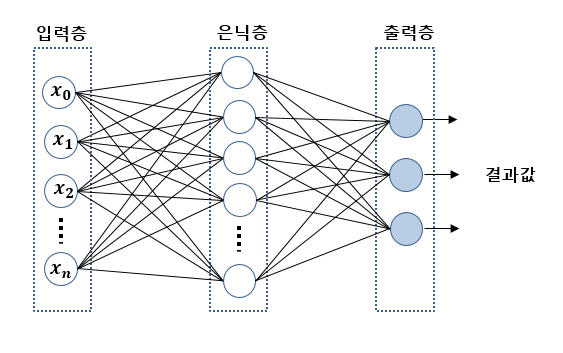
-
정보는 왼쪽에서 오른쪽 한 방향으로 전달, 순서대로 각 층을 l = 1, 2, 3으로 표기
l = 1인 층을
입력층l = 2인 층을
중간층또는은닉층l = 3인 층을
출력층이라고 한다.
- 중간층에선 x를 입력으로 받는데, 그 다음 층에서는 중간층의 출력을 입력으로 받는다.
- 각 층에서 서로 다른 활성화 함수를 사용하여도 무방하다. 특히 출력층 유닛의 활성화 함수는 일반적으로 중간층과는 다른 활성화 함수를 사용한다.
-
하나의 입력 x에 대하여 바람직한 출력을 d라고 할 때, 이러한 입출력 쌍이 어러개 주어졌다고 하면
신경망의 출력 y이 최대한 d와 가까워지도록 w를 조정해야한다. 이것을
학습이라고 부른다.이 때 신경망이 나타내는 함수와 훈련 데이터와의 가까운 정도 즉 거리를 어떻게 측정할 것인지가 중요한데
이 거리의 척도를
오차함수라고 부른다.
- 오차함수 = 손실함수 (나쁜 정도를 측정하는 함수라 보면 될듯 작을수록 좋다!)
| 문제의 유형 | 출력층에 쓰이는 활성화 함수 | 오차함수 |
|---|---|---|
| 회귀 | 항등사상 | 제곱오차 |
| 이진 분류 | 로지스틱 함수 | 식 2-8 |
| 다클래스 분류 | 소프트맥스 함수 | 교차 엔트로피 |
클래스 분류란 입력 x를 내용에 따라 유한개의 클래스로 분류하는 문제.
신경망의 출력층에 분류하려는 클래스 수 L과 같은 수의 유닛을 구성, 이 층의 활성화 함수를 소프트맥스로 선택.
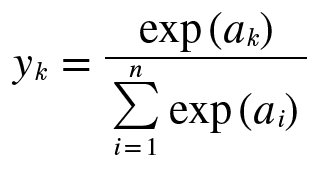
소프트맥스 함수에서는 이 층 모든 유닛의 총 입력으로부터 결정되는 점이 다른 함수들과 다르다.
출력 y1 y2 ... yn 총합이 항상 1이 되는 것에 주의
-
학습의 목표는 선택한 오차함수에 대하여 최솟값을 주는 오차함수를 구하는 것이지만,
오차함수는 일반적인 경우 볼록함수가 아니므로 전역극소점(global minimum)을 직접 구하는 것은 통상적으로 불가능하다.
대신에 국소 극소점(local minimum)을 구하는 것을 생각해보면, 국소 극소점은 여러개 존재하므로
구한 극소점이 우연히 전역 극소점일 가능성은 낮다. 다만 국소 극소점이 충분히 작다면 목적으로 하는 클래스 분류나
회귀 문제를 나름대로 잘 풀 수도 있다.

-
현재의 w를 음의 기울기 방향으로 조금씩 움직이는 것을 여러번 반복하여 언젠가는 극소점에 도달하는 것이다.
최소화 방법에 목적함수의 2차미분을 이용하는 뉴턴법 등이 있지만 문제의 크기가 큰 경우에 2차 미분에 대한 계산이
어렵기에 경사하강법은 사용할 수 있는 몇 안되는 유효한 방법 중 하나가 된다.
-
위에서는 각 샘플의 오차들의 합을 이용하여 한 방법인데, 이를
배치학습이라고 한다. = 에포크 학습확률적 경사하강법은 이와 대조적으로 샘플의 일부, 극단적으론 샘플 하나만을 사용하여 파라미터를 업데이트 한다.1회 진행할때마다 다른 샘플을 선택하여 업데이트를 한다.
배치학습과 비교하여 장점은
-
훈련 데이터에 잉여성이 있을 때 계산 효율이 향상되고 학습이 빨리 진행된다.
-
국소 극소점에 갇히는 위험을 줄일 수 있다. 목적함수가 w를 업데이트할 때마다 달라지므로.
-
-
샘플 전체를 선택 : 경사하강법 / 배치학습
샘플 1개를 선택 : 확률적 경사하강법
샘플 여러개를 선택 : 미니배치
-
미니배치의 크기를 결정하는 통계적인 방법이 따로 있지는 않지만, 확률적 경사하강법의 장점과 병렬 계산 자원의 유효한 이용을 비교하여
대체로 10~100개 샘플 전후로 결정하는 경우가 많다.
-
다클래스 분류 문제에서는 미니배치 간의 가중치 업데이트 값을 일정하게 하기 위해 미니배치마다 각 클래스의 샘플이 하나 이상 들어가도록 하는 것이 이상적
따라서 클래스 수가 10~100개 정도이면서 각 클래스의 출현 빈도가 서로 같을 때에는 분류하려는 클래스 수와 같은 크기의 미니배치를 생성하는 것이 좋다.
- 미니 배치의 크기를 너무 작게 잡는 것은 별로 좋지 않다. (확률적 경사 하강법의 장점을 완전히 활용하지 못하게 하므로)
- 크기를 크게할수록 학습이 빨라지지만 계산속도(단위시간당 업데이트 횟수)는 오히려 느려진다.
- 학습의 진짜 목적은 이미 주어진 훈련 데이터가 아니라 앞으로 주어질 '미지의' 샘플 x에 대한 정확한 추정을 가능토록 하는 것
-
훈련 데이터에 대한 오차
훈련오차(training error)샘플 모집단에 대한 오차에 대한 기댓값
일반화 오차(generalization error)
-
일반화 오차가 작도록 하는 것이 목표이지만, 일반화 오차는 통계적인 기댓값이므로 훈련 오차처럼 계산할 수가 없다.
그러므로 훈련 데이터와 다른 별도의 샘플 집합을 준비한 후, 이 샘플 집합에 대해서 훈련 오차와 같은 방법으로 계산한 오차를 기준으로 삼는다.
이를 목적으로 준비하는 데이터를
테스트 데이터(test data), 테스트 데이터에 대한 오차를테스트 오차(test error)
-
학습곡선: 학습에 의한 파라미터 변화에 따라 훈련 오차 및 테스트 오차가 어떻게 변화하는지에 대한 곡선
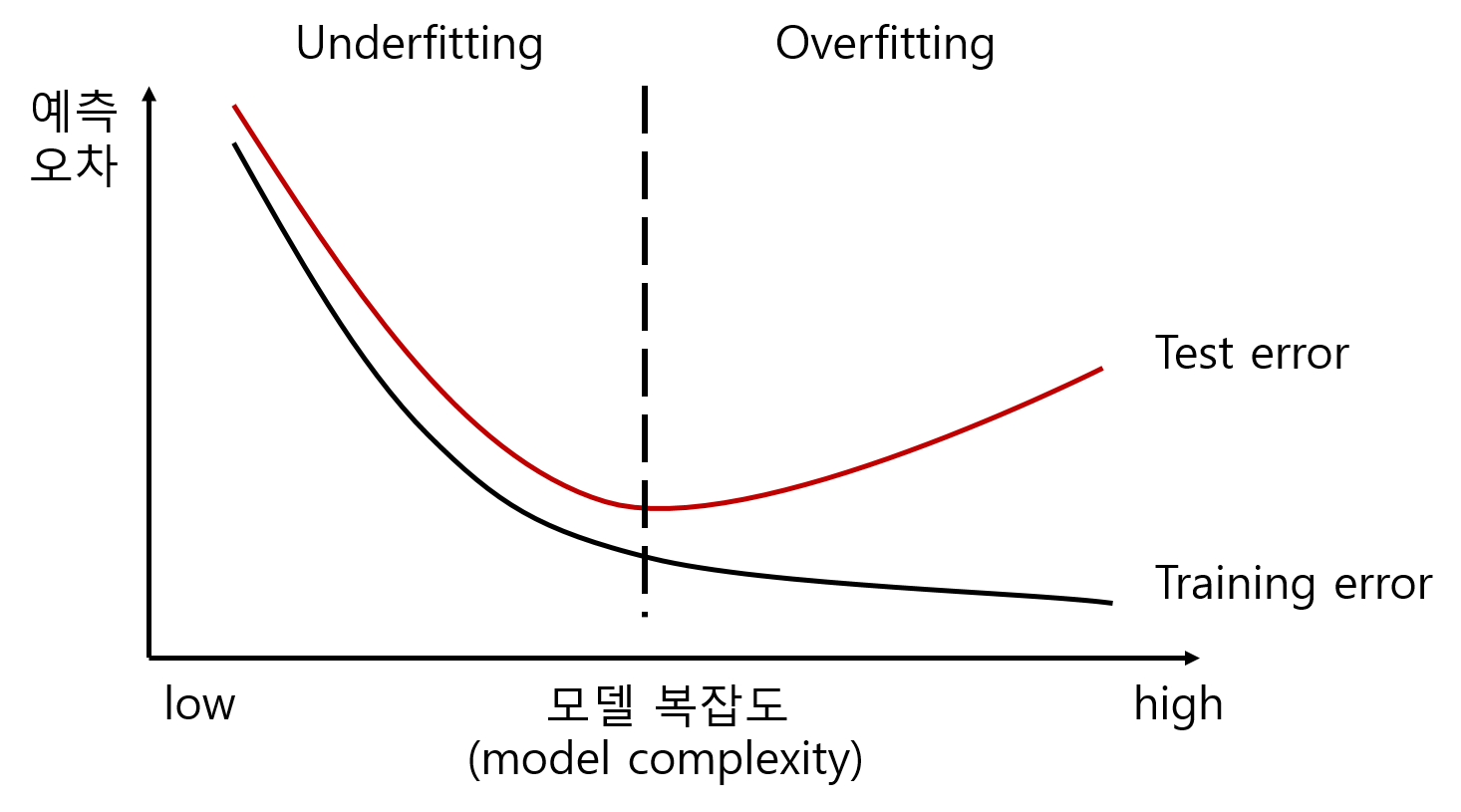
일반적으로 훈련 오차는 파라미터의 업데이트를 반복함에 따라 대개 단조적으로 감소한다.
그에 비해 테스트 오차는 학습 초기에는 훈련 오차와 같이 감소하다가 학습도중에 자주 훈련오차와 많이 달라진 값을 갖게된다.
-
과적합(overfitting): 훈련 오차와 일반화 오차가 동떨어진 값을 갖는 상태가 되는 것
-
조기종료(early stopping): 파라미터 업데이트에 따라 테스트 오차가 증가한다면 더 이상의 학습은 오히려 방해가 되기에 그 시점에서 학습을 종료
-
과적합이란 학습 시에 오차함수 값이 작은 국소 극소점에 갇힌 상황이라고 해석할 수 있다.
신경망의 자유도(주로 가중치의 수)가 높을수록 그럴 가능성이 높다고 할 수 있다.
다만 신경망의 자유도는 그 표현 능력과 직결된다.
학습 시에 가중치의 자유도를 제약하는 규제화(regularization)에 의해 과적합 문제를 완화시키는 방법 : 가중치 감쇠, 가중치 상한, 드롭아웃
-
오차함수에 가중치의 제곱합(norm의 제곱)을 더한 뒤 이를 최소화 하는 방법.
가중치는 자신의 크기에 비례하는 속도로 항상 감쇠하도록 업데이트된다.
- 가중치 감쇠는 가중치 W에만 적용하며 바이어스b에는 적용하지 않는다.
-
각 유닛의 입력 측 결합의 가중치에 대해서 그 제곱합의 최댓값을 제약하는 방법
$ \sum_i w_{ji}^2 < c $
이 부등식을 만족하지 않는 경우에는 가중치에 미리 정한 (1보다 작은) 상수를 곱하여 부등식을 만족하도록 한다.
- 가중치 감쇠보다 뛰어난 효과, 드롭아웃과 함께 사용하면 특히 높은 효과.
- 드롭아웃 : 다층 신경망의 유닛 중 일부를 확률적으로 선택하여 학습하는 방법
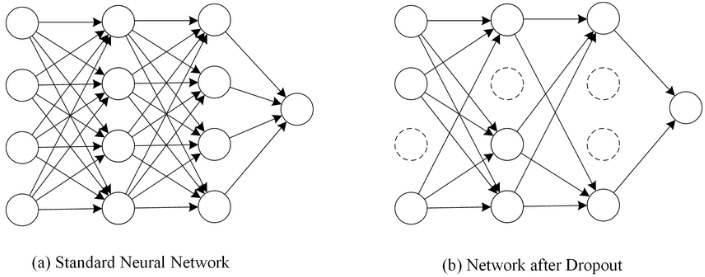
-
학습 시
중간층과 입력층 각 층의 유닛 중 미리 정해둔 비율 p만큼을 선택하고 선택되지 않은 유닛을 무효화.
가상의 신경망을 구성하는 유닛은 가중치를 업데이트할 때 마다 다시 무작위로 선택
-
추론 시
모든 유닛을 사용하여 앞먹임 계산을 한다.
드롭아웃에서 무효화된 유닛은 일률적으로 출력을 p배로 한다. 추론시의 유닛 수가 학습 시에 비해 1/p배 된 것과 같기 때문에 이를 보상하기 위함
(추론 시가 학습시보다 유닛 수가 많음.)
- 드롭아웃이 목적하는 바 : 신경망의 자유도(가중치의 수)를 강제적으로 낮추고 과적합을 회피하는 것
-
이 과정은 드롭아웃을 거친 신경망을 여러 개 훈련한 후 여러개의 신경망으로 부터 얻은 결괏값의 평균을 내는 것과 같은 효과가 있다고 볼 수 있다.
다수의 신경망의 평균을 내면 추론의 정확도가 일반적으로 좋아진다고 알려져 있으며 드롭아웃은 같은 효과를 보다 적은 계산 비용으로 얻을 수 있는 방법이라 볼 수 있다.
-
학습 시에 적용하는 것만으로도 일반화 성능을 향상시키거나 학습을 빨리 진행할 수 있게 하는 방법
-
이론적 뒷받침이 부족한 노하우에 가까운 것들. 실제로 효과를 인정받는 것이 많아 오래전부터 사용됐다.
- 데이터에서 경향을 제거하기 위한 전처리
-
각 성분에서 해당 성분의 학습데이터 전체에서 평균을 빼서 평균이 0이되도록 변환한 뒤 각 성분을 표준편차로 나눈다.
각 성분의 평균이 0, 분산이 1이됨
-
훈련 데이터의 부족은 과적합을 일으키는 가장 큰 원인.
-
데이터 확장 : 확보한 샘플 데이터를 일정하게 가공하여 양적으로 '물타기' 하는 방법
-
데이터 확장은 샘플의 분포 양상을 예상할 수 있는 경우에 특히 유효하다. 이미지 데이터가 그 전형적인 예
- 여러개의 서로 다른 신경망을 조합하면 일반적으로 추정의 정확도를 향상시킬 수 있다.
-
조합할 신경망은 같은 데이터로 훈련한 서로 구조가 다른 것들로 구성하거나 구조가 같아도 서로 다른 초깃값으로 초기화한 것으로 구성.
입력에 서로 다른 변환을 가해 두고 각각 다른 신경망에 입력하여 결과를 평균 내는 방법도 있음.
학습 시에 각 신경망은 서로 독립적으로 훈련
-
단점 : 복수의 신경망을 학습시켜야 하므로 시간 및 연산량이 증가
-
위에서의
드롭아웃은 신경망 하나를 사용해서 실질적으로는 여러개의 신경망에 모델 평균을 적용한 것과 같은 효과가 있다
-
경사 하강법에서는 파라미터의 업데이트 정도를 학습률을 통해 조절
-
학습률을 결정하기 위한 정석과 같은 방법 2가지
-
학습 초기에 값을 크게 설정했다가 학습의 진행과 함께 학습률을 점점 줄여가는 방법
-
신경망의 모든 층에서 같은 학습률을 사용하는 것이 아닌 층마다 서로 다른 값을 사용하는 것
- 각 층의 가중치 업데이트 속도가 되도록 비슷하게 가중치를 설정하는 것이 좋다고 알려져 있다.
- 로지스틱 함수처럼 치역이 제약된 활성화 함수를 사용할 때 특히 중요하다.
- 램프 함수를 사용할 때는 적합하지 않다.
-
- 학습률을 자동적으로 결정하는 방법 :
AdaGrad- 자주 나타나는 기울기의 성분보다 드물게 나타나는 기울기의 성분을 더 중시해서 파라미터를 업데이트 하는 것
-
가중치의 업데이트 값에 이전 업데이트 값의 일정 비율을 더하는 방법
-
오차 함수가 깊은 골짜기 같은 형상을 가지며, 그 골짜기 바닥이 비교적 평평한 경우에는 경사 하강법의 효율이 매우 떨어진다고 알려져있다.
모멘텀은 이러한 문제를 해결하고 골짜기 방향을 따라 골짜기 바닥을 효율적으로 탐색할 수 있게 해준다.
- 가장 일반적인 방법은 가우스 분포로부터 랜덤값을 생성하여 초깃값으로 삼는 방법. 가우스 분포의 표준편차의 선택은 학습에 결과에도 영향을 미친다.
- 표준편차를 그게 잡고 초깃값을 들쭉날쭉하게 하면 초기 학습은 빠르게 진행되지만 오차함수의 감소가 일찌감치 멈춰버리는 경향이 있음
- 바이어스의 초깃값은 통상 0으로 결정
-
유닛의 활성화 함수로 로지스틱 함수 등 치역에 상하한이 있는 함수를 쓰는 경우 표준편차의 범위도 필연적으로 제약을 받는다.
표준편차의 값이 적절하지 못하면 활성화 함수의 출력이 그 치역 내에서 적절한 범위로 들어오지 못하기 때문.
- 표준편차가 너무 작으면 0으로 채운 초깃값을 사용하는 것과 차이가 없게됨.
- 표준편차가 너무 크면 유닛의 입력에 대한 총합이 너무 들쭉날쭉해서 유닛의 출력이 치역의 최댓값 혹은 최솟값을 갖는 경우가 너무 많음
- 이 외에도 사전훈련을 통해 초깃값을 정하는 방법이 있으며 딥 뉴럴넷에서는 이쪽이 더 일반적
-
확률적 경사 하강법을 쓸 때 훈련 샘플을 어떤 순서로 추출할 것인지에 대해 자유롭게 선택할 수 있다.
-
일반적으로는 신경망이 '익숙하지 않은' 샘플을 먼저 보이는 전략이 학습에 가장 유리하다고 할 수 있다.
이 방법은 특히 유형별로 샘플 수에 편차가 있는 클래스 분류 문제에 좋은 결과를 보이곤 한다.
하지만 훈련 데이터 중에 오답(잘못된 목표출력)이 포함된 경우에는 오히려 역효과가 나니 주의가 필요하다.
-
그러나 딥 뉴럴넷을 대상으로 하는 최근의 케이스에서는 클래스 간의 샘플 수에 편차가 없도록 셔플링한 샘플을 기계적으로 조합하여 미니배치를 구성,
미니배치를 구성한 순서대로 반복하여 신경망에 입력하는 경우가 많다.
대규모 신경망과 대량의 훈련 샘플을 어떻게 효율적으로 다룰지에 중점을 더 두는 경우가 많다고 할 수 있다.
-